Jetson AGX Orin(32GB)にコーディングエージェント用のLLMサーバを立てる - Sat, May 2, 2026
Writer: 近藤 鯛貴
Jetson AGX Orin(32GB)にClaude Codeで使えるQwen3.6-35B-A3BのLLMサーバを立てたので手順を記載します。
弊社ではChatGPT Businessプランを契約しており、最近は自社開発を中心にCodexを活用しています。
Businessプランではプロジェクトの規模が大きくなるにつれて利用上限にすぐ達してしまうようになり、より手軽に使えるローカルLLM環境を探すようになりました。
いくつか試してみた結果、Jetson AGX Orin 環境ではClaude Code + llama-serverの構成が最適という結論になりました。
環境構築
llama.cppをビルドする
git clone git@github.com:ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
モデルのダウンロード
今回はunsloth/Qwen3.6-35B-A3B-GGUFのQwen3.6-35B-MXFP4_MOE.ggufを使います
wget -O Qwen3.6-35B-A3B-MXFP4_MOE.gguf https://huggingface.co/unsloth/Qwen3.6-35B-A3B-GGUF/resolve/main/Qwen3.6-35B-A3B-MXFP4_MOE.gguf?download=true
サーバを立てる
Jetsonではmmapを無効にしないと10GB程度のモデルでOOMが発生します。
ollamaやlmstudio cliではこの設定ができなさそうかつCodexではllama-serverが使えないので今回この構成になっています。
./build/bin/llama-server \
-m path/to/Qwen3.6-35B-A3B-MXFP4_MOE.gguf \
--alias "unsloth/Qwen3.6" \
--host 0.0.0.0 \
--port 8000 \
--n-gpu-layers 999 \
--ctx-size 256000 \
--batch-size 512 \
--no-mmap
Claude Codeから使う
export ANTHROPIC_BASE_URL=http://<Jetson IP Address>:8000
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1
export DISABLE_NON_ESSENTIAL_MODEL_CALLS=1
claude # Claude Code cliを実行
これで動作します
試してみる
Pygameでテトリスを実装させてみました。1回の指示で遊べるものが出てきました
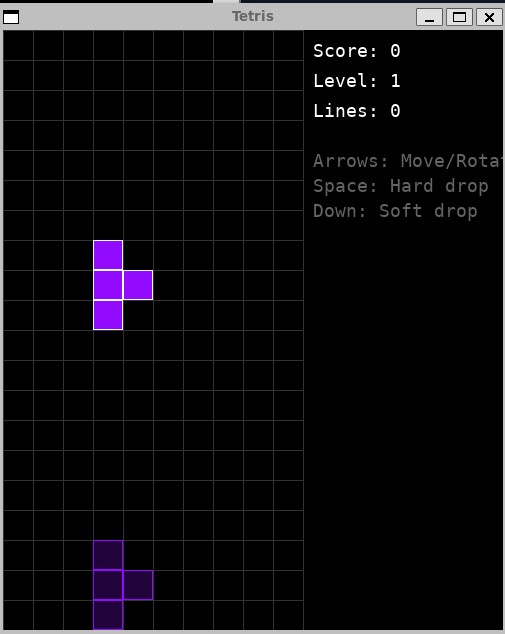
処理速度は以下です。
prompt eval time = 469.31 ms / 74 tokens ( 6.34 ms per token, 157.68 tokens per second)
eval time = 8038.26 ms / 218 tokens ( 36.87 ms per token, 27.12 tokens per second)
total time = 8507.57 ms / 292 tokens
生成で27tps出ています。個人用だったら十分使えそうですね。